It should exist. It’s everywhere. And yet — hard to pin down.
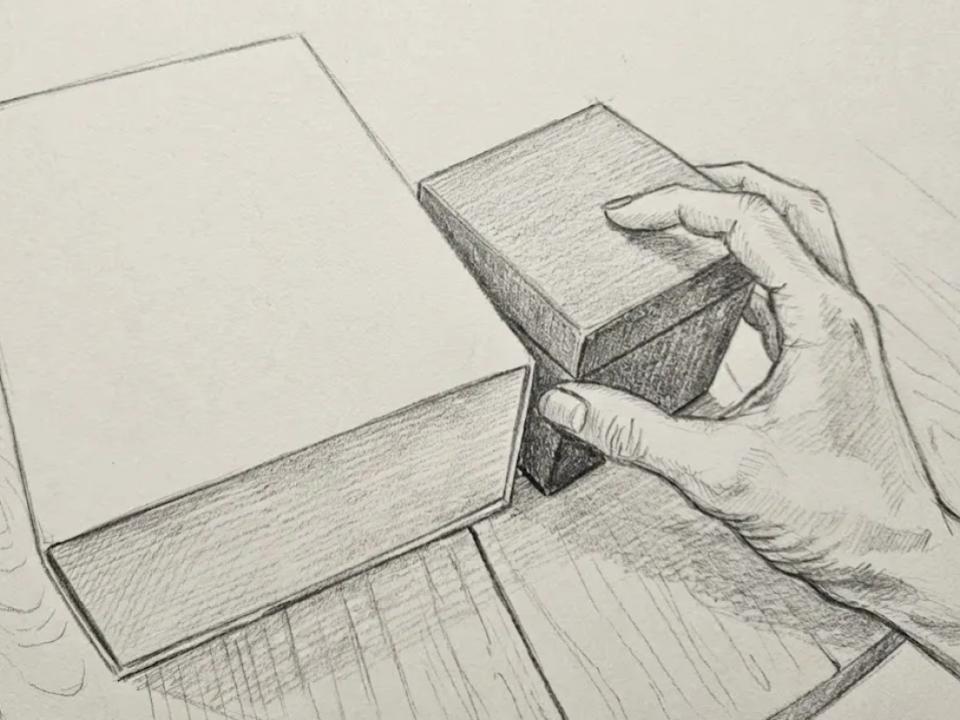
The next time you grab an object tightly packed on a shelf — like a book or a box — watch what your hands do. Do you nudge it sideways to make room for your fingers? Slide it to the edge before lifting? If something heavy starts to slip, do you briefly set it down to get a better grip?
These moves are subtle and automatic. We rarely notice them, but they’re doing a huge amount of work. From the tiny corrections, recoveries, and the “obvious” actions — together they account for much of our extraordinary ability to manipulate the physical world.
This is physical commonsense. It is the reactive, closed-loop intelligence behind acting in the real world: an intuition for forces, friction, compliance, and uncertainty, learned through a lifetime of sensorimotor experience, compiled into reflex and muscle memory. It’s what lets us adjust mid-action, correct mistakes without thinking, and recover from surprises before they become failures.
It’s everywhere, but what feels like second nature to us is hard for machines — difficult to describe, impossible to program.
Easy for humans, hard for machines
This idea has shown up many times under different names. In 1966, Michael Polanyi described it as tacit knowledge1 — knowledge that is difficult to articulate with words, known only through doing, using the body as an instrument to know the world (e.g. riding a bicycle, or kneading dough). In 1988, Hans Moravec pointed out a related paradox:2 that the skills evolution optimized first in humans — sensorimotor control and physical interaction — are precisely the hardest for machines to replicate.
Decades later, this paradox persists. Machines excel at computational tasks, yet struggle to internalize the nuanced physical competence of a toddler. Industrial robots can repeat pre-programmed motions with millimeter precision in controlled settings, but when presented with anything that is even slightly unstructured — slippage, clutter, deformable objects, uncertainty — they often fail in ways that feel profoundly unhuman.3
Why models trained on the Internet don’t get physical commonsense
Polanyi’s point cuts deep here: physical commonsense is hard to describe because it is not linguistic. It does not live in propositions — it lives in the loop between sensing and action.
Models trained on Internet text (and images) can learn a specific kind of semantic commonsense: statistical regularities and patterns over words, facts, and symbols. Completing the phrase “the boy went to the _” yields about 40% “playground”, 30% “school,” etc., probabilities over the next word that reflect information priors generally shared (i.e. written) by most people. When these models are scaffolded appropriately (as research from our team has shown in the past), they can generate plans,4 code,5 or high-level action sequences,6 sometimes used on robots. But this is not physical commonsense.
The missing ingredient is closed-loop interaction. Internet data has no proprioception, no intervention, no consequence. No slipping object. No corrective reflex. Studying the DMV manual online gives useful background knowledge, but it is not the same as the real experience of learning how to drive on the road (and acquiring the kind of commonsense that comes with it).
Physical commonsense is learned through physical experience
Physical commonsense emerges from the sensorimotor loop. And in the process of interacting with the world, action produces information: an agent observes the outcome, collapses uncertainty about the world, and updates a prior of what to do next. Intelligence forms not only by reading, but by acting.
A child pouring water does not learn from description, but from sensation — the container getting lighter, water splashing on fingers, surfaces becoming slippery, grips failing and adapting. These are not annotations. They are experiences. The concept of a container, water, and slippery become grounded in consequences.
Data can create commonsense — if it’s the right data
Language models however, did teach us something important: that commonsense can emerge from scale. Over-parameterized models trained on large, diverse datasets exhibit a kind of spectral bias7 — learning simple patterns that generalize across data samples, a structure with which commonsense can be statistically captured.
The same may be true in robotics. If large-scale text yields semantic commonsense, then large-scale physical interaction may yield physical commonsense.
But only if the data preserves the loop.
Much of robot data today comes from remote control teleoperation (been around since the 1950s).8 However, teleoperation often breaks the sensorimotor loop: latency, limited tactile feedback, and unnatural interfaces push operators away from fast, reactive control (System 1 thinking)9 and towards slow, deliberate planning (System 2 thinking)9 e.g. “put one finger here... then another finger there...” The resulting trajectories are stiff and stilted. Training models to imitate these trajectories can result in robots that hit a wall: they become jagged and slow. While recorded trajectories can be artificially “sped up,” there will be an obvious mismatch between the dynamics of the observations, and how the robots should react (e.g. an object does not actually fall twice as fast).
The exception is data collection so seamless that it preserves natural human behavior — as though the mind of the operator can act directly through instincts refined over millions of years.
At Generalist, we built lightweight handheld, ergonomic devices that let people manipulate objects almost as they would with their own hands. These devices feel balanced, and the force feedback is there — after a few minutes of doing a task, operators stop “thinking” and start reacting.
The results look different. People knit, peel potatoes, paint miniatures.10 Not only does it expand the scope of tasks possible to get robot data on, the data itself captures reflexes, micro-corrections, and real-time recovery. Our models trained on this data produce robot behaviors that people consistently describe as “human-like.” This is not an accident.
Early signs of physical commonsense
As we scale real-world, reactive manipulation data, we’re starting to see a pattern: frontier models pretrained on large, diverse physical interactions adapt faster, transfer better, and require less task-specific tuning to bridge the deployment gap.11
Our own results12 suggest that large-scale robotics pretraining appears to induce a prior over contact-rich interaction — a sense of what comes next — that helps models fill in gaps during downstream learning. Success rates rise. Error recovery improves. Transfer becomes easier.
Physical commonsense is the emergent structure that gives rise to scaling laws in robotics.12
This is what gets me up in the morning: the excitement of walking into office everyday and watching this coming to life. Moments of brilliance when the robot is running and someone just goes “woah… did you see that?” — recoveries that don’t look scripted, corrections that happen “for free,” behaviors that feel less like replaying a trajectory and more like reacting to physics in real time:
This shift from “programmed perfection” to “learned intuition” will be foundational. Classic robotics demands structured environments and millimeter precision. They can be spectacular — until the world gets a tiny bit messy, and they start to break down. Yet, humans succeed without millimeter precision because we carry a learned prior for physical interaction. We adapt, recover, and stay robust under uncertainty. Models trained on the right physical data can give robots the beginnings of that same intuition.
Robots that ship with physical commonsense will be better at just about everything.
Physical commonsense is more than low-level control
A few months ago, we released a demo video of one-shot assembly13 (still a team favorite): you show a robot what to build with LEGO, and it builds copies of that structure. A single sensorimotor model performs moments of physical commonsense — nudging, reorienting, recovering — while doing high-level reasoning around task-level semantics e.g. what comes next and how to place it (in ways that would’ve otherwise been difficult to describe in language).
These capabilities are exciting, because they reveal a hint of what’s to come — a new era of foundation models born from physical experience, that might one day be capable of high-level reasoning just as well as humans can in the physical world. As these models expand in the complexity of tasks and workflows they can do, the boundary between low-level interaction and high-level planning begins to blur.
Embodied systems like these force the full intelligence stack. The world is partially observable, adversarial, and unforgiving. Actions yield information — but also irreversible consequences. High-level reasoning needs to happen in real-time, and gravity stops for no one.
Physical commonsense is the dark matter of robotics: unseen, everywhere, and responsible for most of what actually works. Learning it is the tipping point where robots become broadly useful at scale. We’re still early in the journey, but if we can solve this, then I think we have a real shot at building generally intelligent machines — ones that have the chance to transform not only robotics, but everything that interacts with the physical world.
Real robot intelligence starts with physical commonsense.
Acknowledgements. The analogy here was inspired by Yejin Choi’s work on commonsense intelligence — do check out her work if you haven’t already! Also, Matt Mason’s research continues to be a constant source of inspiration (see his blog posts on the fascinating nuances of dexterous manipulation e.g. in clutter).