Blog / Research
GEN-0 / Embodied Foundation Models That Scale with Physical Interaction
Nov 4, 2025
(Generalist, 2025) 4 Scaling Laws for Transfer (Hernandez et al., 2021) 5 Learning to reason with LLMs (OpenAI, 2024) 6 Helix: A Vision-Language-Action Model for Generalist Humanoid Control (Figure, 2025) 7 Real-Time Execution of Action Chunking Flow Policies (Black et al., 2025) 8 Note that in the LLM literature this phenomenon has been used to refer to the pretrain-to-finetune setting, whereas in our experiments (Figure 1) we observe ossification-type behavior of zero-shot generalization during the pure pretraining phase. 9 Overtrained Language Models Are Harder to Fine-Tune (Springer et al., 2025) 10 Mind Children (Moravec, 1988) 11 Divergence measures and message passing (Minka, 1988) 12 A Divergence Minimization Perspective on Imitation Learning Methods (Seyed Ghasemipour et al., 2019) 13 Imitation Learning as f-Divergence Minimization (Ke et al., 2020)
For years, foundation models in robotics have primarily used vision-language pretraining as the stepping stone towards scaling robotics, allowing us to transfer1 the benefits of semantic generalization from existing large multimodal models. But what's been missing is how to effectively scale large multimodal model training in the domain of robotics itself—to establish scaling laws that corroborate the consistent (and predictable) improvement of robot intelligence with more compute & data, as has underpinned progress in other domains e.g. LLMs.2 This requires an architecture, training procedure, and data engine that pushes new sensorimotor capabilities, provides behavioral generalization, and grows with the vast and ever-expanding experience generated by interacting with the real physical world.
To this end, we’re introducing GEN-0, a new class of embodied foundation models built for multimodal training directly on high-fidelity raw physical interaction. Its architecture builds on the strengths of vision and language models while also going beyond them—natively designed to capture human-level reflexes and physical commonsense. One core feature is Harmonic Reasoning, in which the models are trained to simultaneously think and act seamlessly. We’ve shared a glimpse of the capabilities of early precursors in our prior videos,3 and today we are sharing that not only does GEN-0 have breakthrough fundamental capabilities, but these capabilities are scaling:
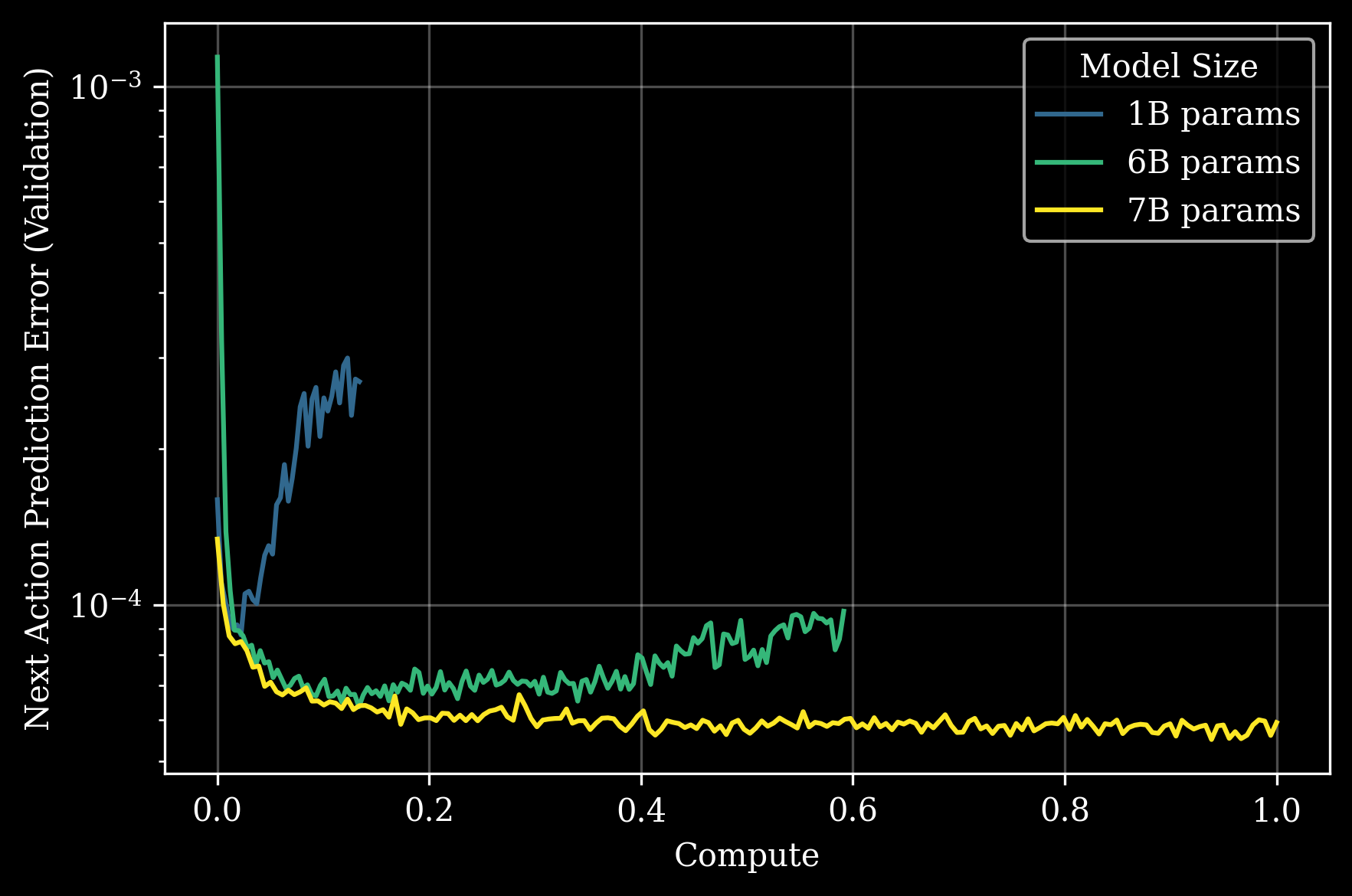
To our knowledge, this is the first time that model ossification8 has been observed in robotics. This might have eluded past research due to (a) the lack of a high data regime in robotics until now, and (b) large enough model sizes in this regime. Ossification has previously been observed in LLM literature4,9 in the high data regime but with much smaller models, on the order of O(10M) parameters rather than O(1B). The observation that this phase transition occurs in robotics but with much larger model sizes echoes Moravec’s Paradox:10 what humans find effortless—perception and dexterity—demands far more computational complexity than abstract reasoning. Our experiments suggest that intelligence in the physical world (i.e. physical commonsense) may have a higher activation threshold in terms of compute, and we’re only beginning to explore what lies beyond.
More specifically, we take a variety of model checkpoints (Figure 2) that have been pretrained using our training procedure on different subsets of our pretraining dataset, and then post-train these checkpoints on multi-task language-conditioned data i.e. supervised fine-tuning simultaneously on 16 different task sets. We find that more pretraining improves downstream model performance across all tasks (Figure 2).
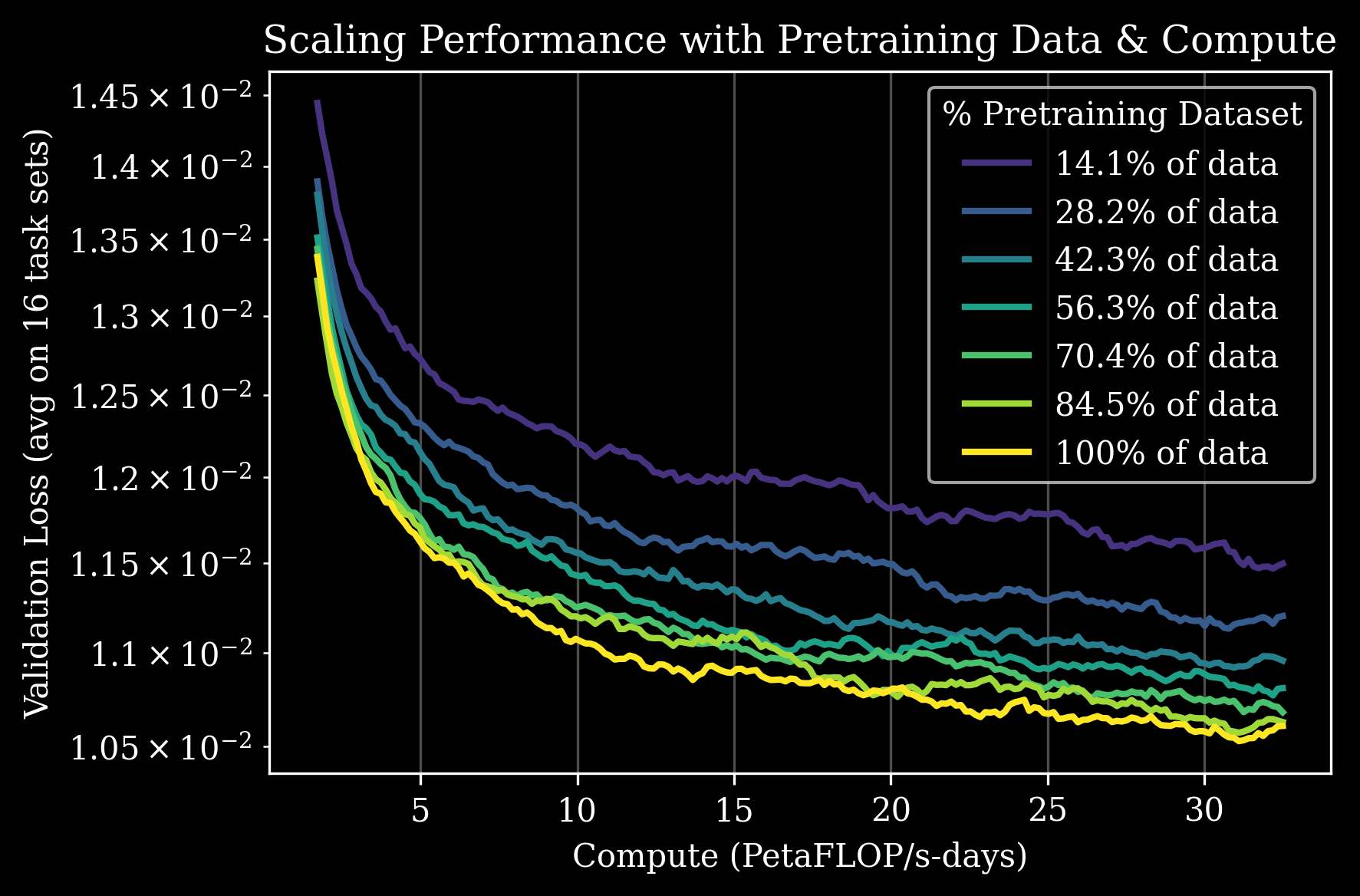
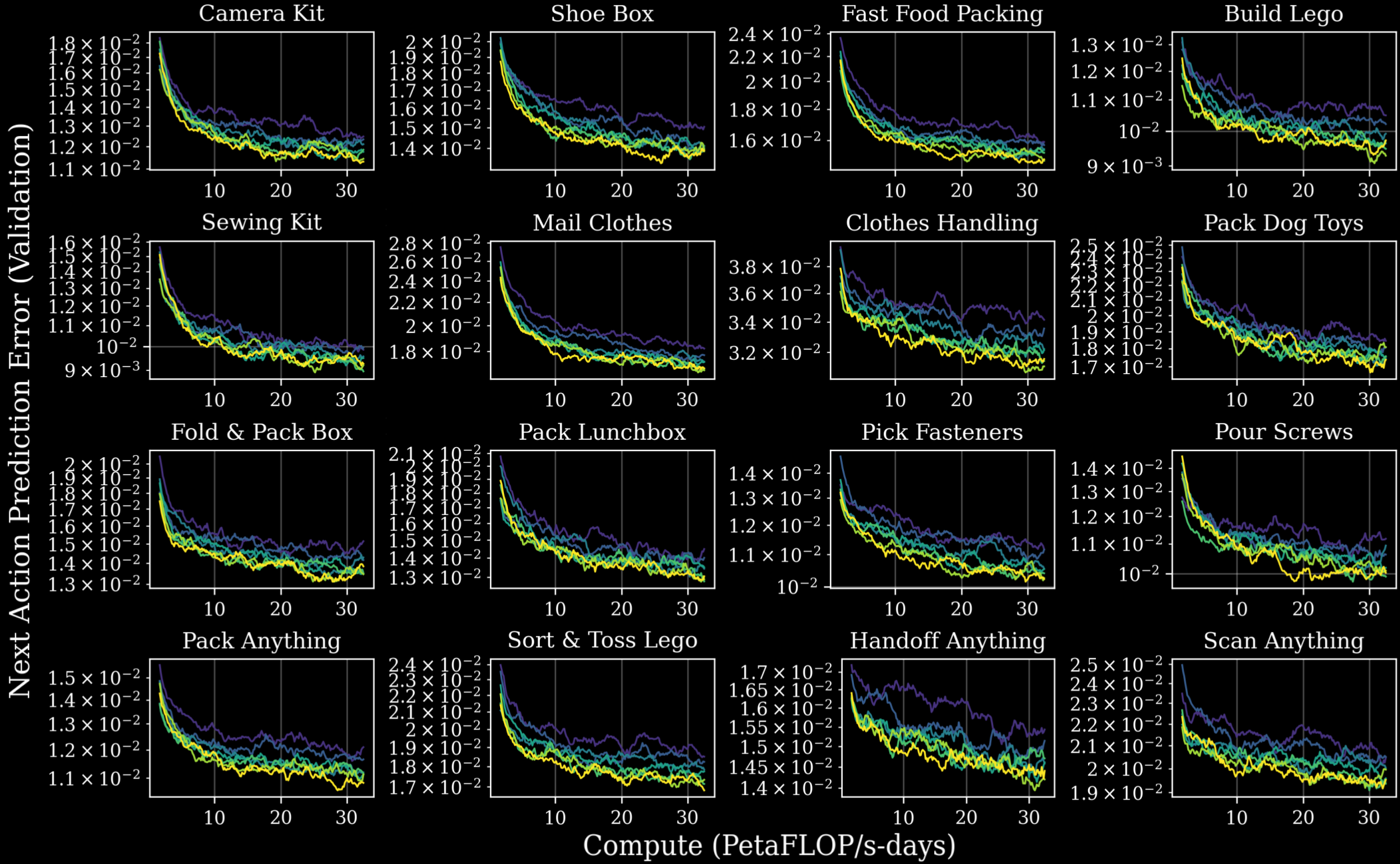
Figure 2. With increasingly more pretraining data (different colors), multi-task model performance during post-training improves in terms of validation loss (top) as well as next action prediction error (bottom 4x4 grid) across all 16 task sets. These tasks include ones that evaluate dexterity (e.g. build Lego), industry-specific workflows (e.g. fast food packing), and generalization (e.g. “_ anything” tasks).
We also observe that these trends transfer to real-robot performance, measured with blind A/B evaluations. Increasing the amount of pretraining data improves downstream task success rates (Figure 3) using closed-loop policies with models post-trained on only 5.6 hours of task-specific data. While the gains are significant in this low-data regime, the highest task success rates (up to 99% peak performance in certain cases) emerge when large-scale pretraining is paired with ample task-specific post-training data. For valid comparisons, we ensured no overlap between the pretraining and post-training datasets, which were collected by different people in entirely different environments.
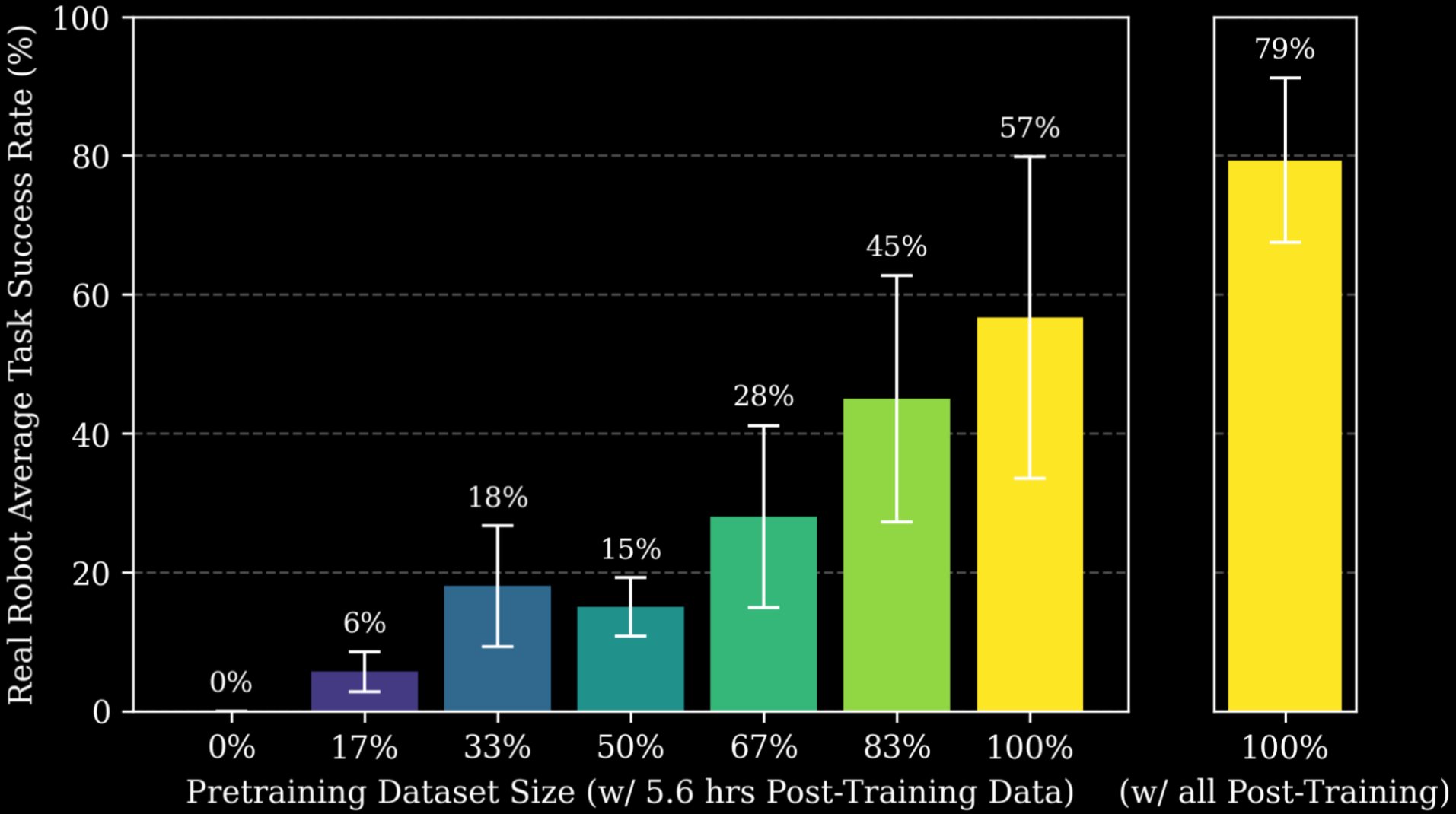
Figure 3. For real-robot evaluations, more pretraining data (colors denote different pretrained model bases) yields higher downstream average task success rates via closed-loop policy rollouts (performance is plotted with standard error). Models on the left are post-trained on 5.6 hours (1%) of task-specific data, and the best models (right) use both the full pretraining dataset and all (550+ hours) of available task-specific post-training data.
Model performance is predictable with a power-law relationship (Figure 4), with which we can answer questions like “how much pretraining data do we need to reach a specific next-action prediction error?” or “how much post-training data (for a specific task) can we buy with more pretraining data?” Given a fixed data and finetuning budget on a downstream task, and given a pretraining dataset of varying size \(D\), the validation error \(L(\cdot)\) on the downstream task can be predicted via a power-law of the form: $$ L(D) = (D_c / D)^{\alpha_{D}} \ . $$ For example, in the case of Clothes Handling (which involves sorting, unscrambling, buttoning, and hanging clothes in a real workplace), we can predict model performance given 1 billion action trajectories. These estimates guide conversations on partner-related tasks and can provide estimates on how much more data is needed to reach specific levels of performance.
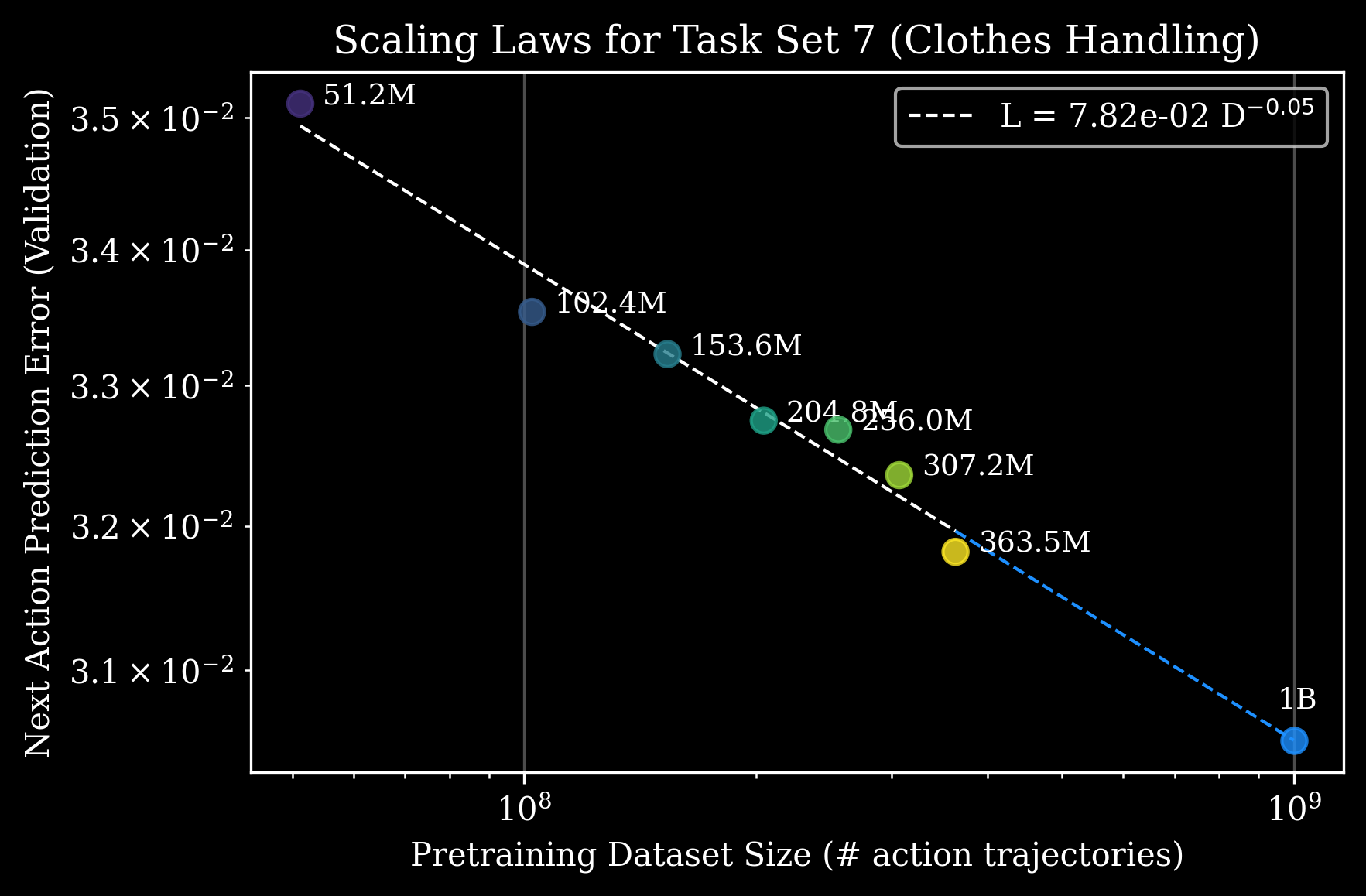
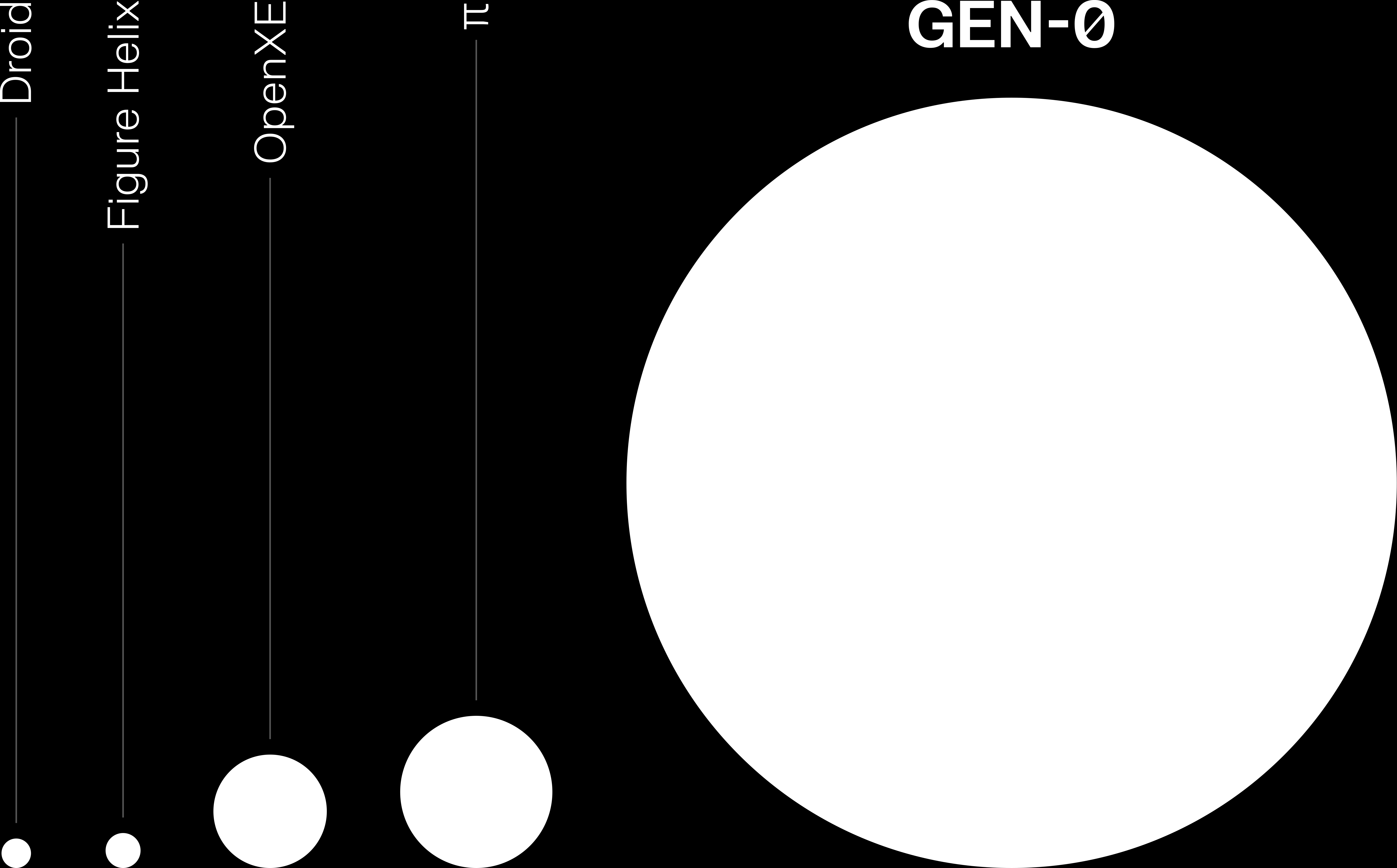
Figure 5. GEN-0 is trained on orders of magnitude more real-world manipulation data than some of the largest robotics datasets that exist to date (as of Nov 2025).
Performance is measured in terms of validation prediction M.S.E. \(\text{MSE}_{\text{val}} = ||\mathbf{a}^{\star} - \hat{\mathbf{a}}||_2^2 \) and reverse Kullback–Leibler divergence11 (reverse KL), which better measures mode-seeking behavior.12,13 To estimate reverse KL, we use a Monte-Carlo estimator where the policy induces an empirical density \(q =\frac{1}{M}\sum_{m=1}^{M}\mathcal{N}\left(\mathbf{a}; \hat{\mathbf{a}}_{m},\mathbf{I}\right)\) via a unit-variance mixture of Gaussians centered at \(M\) policy samples \(\{\hat{\mathbf{a}}_m\}_{m=1}^{M}\), and the data/ground-truth induces a unit-variance Gaussian \(p(\mathbf{a})=\mathcal{N}\left(\mathbf{a}; \mathbf{a}^\star,\mathbf{I}\right) \) centered at \(\mathbf{a}^\star\). We approximate the expectation with policy samples: $$ \widehat{D}_{\mathrm{KL}}(q||p) \approx \frac{1}{M}\sum_{m=1}^{M}\Big[\log q(\hat{\mathbf{a}}_{m})-\log p(\hat{\mathbf{a}}_{m})\Big] \ . $$ Experiments show that models with both low prediction errors and low reverse KL tend to perform better with supervised finetuning (SFT) for postraining, while models with high prediction errors and low reverse KL tend to be more distributionally multimodal, which can help post-training reinforcement learning. Having multiple data collection strategies at scale allows us to continually A/B test which data improves pretraining the most.
More on these learnings in future posts.
To this end, we’re introducing GEN-0, a new class of embodied foundation models built for multimodal training directly on high-fidelity raw physical interaction. Its architecture builds on the strengths of vision and language models while also going beyond them—natively designed to capture human-level reflexes and physical commonsense. One core feature is Harmonic Reasoning, in which the models are trained to simultaneously think and act seamlessly. We’ve shared a glimpse of the capabilities of early precursors in our prior videos,3 and today we are sharing that not only does GEN-0 have breakthrough fundamental capabilities, but these capabilities are scaling:
- Surpassing the Intelligence Threshold – in an unprecedented high-data regime for robotics, we observe a phase transition at 7B where smaller models exhibit ossification,4 while larger ones continue to improve. We’ve since scaled GEN-0 to 10B+ model sizes, and observe fast adaptation to new tasks with increasingly less post-training.
- Scaling Laws – GEN-0 models exhibit strong scaling laws, in which more pretraining data and compute consistently (and predictably) improve downstream post-training performance of the model across many tasks.
- Harmonic Reasoning - Although for language chatbots it is straightforward to spend more time thinking before responding,5 the same is not as simple for physical systems acting in the real world – physics doesn't stop. To address this problem, Harmonic Reasoning involves a fundamentally new approach to training models, and creates a "harmonic" interplay between asynchronous, continuous-time streams of sensing and acting tokens. This allows us to scale to very large model sizes without depending on System1-System2 architectures6 or inference-time guidance.7
- Cross-Embodiment – GEN-0 architecture works on different robots by design. We have tested our models on 6DoF, 7DoF, and 16+DoF semi-humanoid robots.
- No Longer Limited By Data – GEN-0 is pretrained on our in-house robotics dataset, which includes over 270,000 hours of real-world diverse manipulation data, growing at a rate of 10,000 hours a week and accelerating.
- The Science of Pretraining – different mixtures of pretraining data (from various sources e.g. data foundries) yield GEN-0 models with different characteristics. We share some early notes from our empirical observations in this high-data regime, and how that traces back to specific data collection operations.
Build a camera kit (top view). This is a long horizon dexterous task that involves placing a cleaning cloth into a box, folding in a cardboard tray, picking up a camera and unsheathing it from a plastic bag, placing it into the box, closing the box (and inserting the tiny flap), then discarding the plastic bag. The model does not maintain any explicit notion of a subtask, and performs this all within a single stream of harmonic reasoning.
Surpassing the Intelligence Threshold
Our scaling experiments show that GEN-0 models must be large enough to absorb vast amounts of physical interaction data. We observe that smaller models exhibit a phenomenon similar to ossification4 under data overload, while larger ones continue to improve—demonstrating a surprising “phase transition” in the intelligence capacity of our models:- 1B models struggle to absorb complex and diverse sensorimotor data during pretraining – model weights become unable to absorb new information over time.
- 6B models begin to benefit from pretraining and show strong multi-task capabilities.
- 7B+ models are able to internalize large-scale robotic pretraining data that transfers to downstream tasks with only a few thousand steps of post-training.
Figure 1. Scaling GEN-0 model size (different colors) improves performance in terms of next-action validation prediction error (y-axis, lower is better) on a completely-withheld (i.e. zero-shot) long-horizon downstream task. 1B parameter models exhibit clear and early ossification, while 6B and 7B models perform better at absorbing pretraining respectively. The x-axis is pretraining compute normalized so that GEN-0 7B is 1.0.
To our knowledge, this is the first time that model ossification8 has been observed in robotics. This might have eluded past research due to (a) the lack of a high data regime in robotics until now, and (b) large enough model sizes in this regime. Ossification has previously been observed in LLM literature4,9 in the high data regime but with much smaller models, on the order of O(10M) parameters rather than O(1B). The observation that this phase transition occurs in robotics but with much larger model sizes echoes Moravec’s Paradox:10 what humans find effortless—perception and dexterity—demands far more computational complexity than abstract reasoning. Our experiments suggest that intelligence in the physical world (i.e. physical commonsense) may have a higher activation threshold in terms of compute, and we’re only beginning to explore what lies beyond.
Scaling Laws for Robotics
Scaling laws are commonly measured during pretraining, as shown in Figure 1, which shows the relationship of model size and compute on a downstream zero-shot task during pretraining. Another type of scaling law relates to the benefits of pretraining that persist into finetuning.4 At sufficient model scale, we also observe a strong power-law relationship (Figure 4) between pretraining data scale and downstream post-training performance. This applies to all of our tasks we've measured, including partner and customer-inspired applications and their workflows across a wide range of industrial sectors – including apparel, manufacturing, logistics, automotive, and electronics.More specifically, we take a variety of model checkpoints (Figure 2) that have been pretrained using our training procedure on different subsets of our pretraining dataset, and then post-train these checkpoints on multi-task language-conditioned data i.e. supervised fine-tuning simultaneously on 16 different task sets. We find that more pretraining improves downstream model performance across all tasks (Figure 2).
Figure 2. With increasingly more pretraining data (different colors), multi-task model performance during post-training improves in terms of validation loss (top) as well as next action prediction error (bottom 4x4 grid) across all 16 task sets. These tasks include ones that evaluate dexterity (e.g. build Lego), industry-specific workflows (e.g. fast food packing), and generalization (e.g. “_ anything” tasks).
We also observe that these trends transfer to real-robot performance, measured with blind A/B evaluations. Increasing the amount of pretraining data improves downstream task success rates (Figure 3) using closed-loop policies with models post-trained on only 5.6 hours of task-specific data. While the gains are significant in this low-data regime, the highest task success rates (up to 99% peak performance in certain cases) emerge when large-scale pretraining is paired with ample task-specific post-training data. For valid comparisons, we ensured no overlap between the pretraining and post-training datasets, which were collected by different people in entirely different environments.
Figure 3. For real-robot evaluations, more pretraining data (colors denote different pretrained model bases) yields higher downstream average task success rates via closed-loop policy rollouts (performance is plotted with standard error). Models on the left are post-trained on 5.6 hours (1%) of task-specific data, and the best models (right) use both the full pretraining dataset and all (550+ hours) of available task-specific post-training data.
Model performance is predictable with a power-law relationship (Figure 4), with which we can answer questions like “how much pretraining data do we need to reach a specific next-action prediction error?” or “how much post-training data (for a specific task) can we buy with more pretraining data?” Given a fixed data and finetuning budget on a downstream task, and given a pretraining dataset of varying size \(D\), the validation error \(L(\cdot)\) on the downstream task can be predicted via a power-law of the form: $$ L(D) = (D_c / D)^{\alpha_{D}} \ . $$ For example, in the case of Clothes Handling (which involves sorting, unscrambling, buttoning, and hanging clothes in a real workplace), we can predict model performance given 1 billion action trajectories. These estimates guide conversations on partner-related tasks and can provide estimates on how much more data is needed to reach specific levels of performance.
Figure 4. Our scaling laws provide a good description for asymptotic next action prediction error on a post-trained model for a given task set as a function of pretraining dataset size (in terms of number of action trajectories). Together with model size scaling laws, we can use these results to predict optimal allocation of pretraining compute and data for any downstream post-training task.
Robotics is No Longer Limited By Data
Our Foundation models are trained on an unprecedented corpus of 270,000 hours of real-world manipulation trajectories collected across diverse activities in 1,000s of homes, warehouses, and workplaces worldwide. Today, our robot data operations provide over 10,000 new hours per week and are accelerating. This is all powered by a global network of hardware and 1,000s of data collection devices and robots.
Figure 5. GEN-0 is trained on orders of magnitude more real-world manipulation data than some of the largest robotics datasets that exist to date (as of Nov 2025).
Mapping the Universe of Manipulation
To scale GEN-0 capabilities, we are constructing the largest and most diverse real-world manipulation dataset ever built, including every manipulation task humans can think of – from peeling potatoes, to threading bolts – spanning homes, bakeries, laundromats, warehouses, factories, and more. Here is an example internal search tool we have built to explore this universe:Figure 6. This is an example of searching through <1% of our pretraining dataset, which includes manipulation data from millions of diverse activities across different environments. The visualization navigates the user through a t-SNE map of corresponding language label embeddings in the dataset. Given a text description, the visualizer locates the nearest neighbor region, and randomly samples in the area a collection of related videos and displays them.
Infrastructure for Internet-Scale Robot Data
Building the operations and ML infrastructure to support this is no easy feat. For robot models and data at this scale, we built custom hardware, dataloaders, and network infrastructure (including laying new dedicated Internet lines) to support the uplink bandwidth from a diverse set of data collection sites all around the world. We’ve negotiated multi-cloud contracts, built custom upload machines, scaled to O(10K) cores for continual multimodal data processing, compressed dozens of Petabytes of data, using dataloading techniques behind frontier video foundation models, capable of absorbing 6.85 years of real-world manipulation experience per day of training.Science of Pretraining
From large-scale ablations, we find that data quality and diversity matters more than sheer volume, and that carefully constructed data mixtures can lead to different pretrained model characteristics. For example, Table 1 shows the performance metrics of different models trained on 8 different pretraining datasets, and their downstream impact when finetuned on 10 long-horizon task sets, organized into 3 groups that evaluate different dimensions: dexterity, real-world applications, and generalization.Performance is measured in terms of validation prediction M.S.E. \(\text{MSE}_{\text{val}} = ||\mathbf{a}^{\star} - \hat{\mathbf{a}}||_2^2 \) and reverse Kullback–Leibler divergence11 (reverse KL), which better measures mode-seeking behavior.12,13 To estimate reverse KL, we use a Monte-Carlo estimator where the policy induces an empirical density \(q =\frac{1}{M}\sum_{m=1}^{M}\mathcal{N}\left(\mathbf{a}; \hat{\mathbf{a}}_{m},\mathbf{I}\right)\) via a unit-variance mixture of Gaussians centered at \(M\) policy samples \(\{\hat{\mathbf{a}}_m\}_{m=1}^{M}\), and the data/ground-truth induces a unit-variance Gaussian \(p(\mathbf{a})=\mathcal{N}\left(\mathbf{a}; \mathbf{a}^\star,\mathbf{I}\right) \) centered at \(\mathbf{a}^\star\). We approximate the expectation with policy samples: $$ \widehat{D}_{\mathrm{KL}}(q||p) \approx \frac{1}{M}\sum_{m=1}^{M}\Big[\log q(\hat{\mathbf{a}}_{m})-\log p(\hat{\mathbf{a}}_{m})\Big] \ . $$ Experiments show that models with both low prediction errors and low reverse KL tend to perform better with supervised finetuning (SFT) for postraining, while models with high prediction errors and low reverse KL tend to be more distributionally multimodal, which can help post-training reinforcement learning. Having multiple data collection strategies at scale allows us to continually A/B test which data improves pretraining the most.
| Partner & Class (Pred Err) | Dexterity | Applications | Generalization |
|---|---|---|---|
| Partner A Class 1 | 0.00307682 | 0.00334155 | 0.00308992 |
| Partner A Class 2 | 0.00306196 | 0.00333253 | 0.00306503 |
| Partner A Class 3 | 0.00305728 | 0.00331309 | 0.00305888 |
| Partner A Class 2 + 3 | 0.00315980 | 0.00341899 | 0.00315661 |
| Partner B Class 1 | 0.00302728 | 0.00330365 | 0.00304627 |
| Partner B Class 2 Objs | 0.00314415 | 0.00341147 | 0.00315975 |
| Partner B Class 2 Skills | 0.00301995 | 0.00329235 | 0.00305292 |
| Partner C Class 3 | 0.00306247 | 0.00332128 | 0.00307944 |
| Partner & Class (Rev KL) | Dexterity | Applications | Generalization |
|---|---|---|---|
| Partner A Class 1 | 0.00200585 | 0.00258898 | 0.00198088 |
| Partner A Class 2 | 0.00188744 | 0.00244642 | 0.00193866 |
| Partner A Class 3 | 0.00198332 | 0.00246089 | 0.00190205 |
| Partner A Class 2 + 3 | 0.00184110 | 0.00228588 | 0.00185473 |
| Partner B Class 1 | 0.00189286 | 0.00246051 | 0.00192307 |
| Partner B Class 2 Objs | 0.00184719 | 0.00233209 | 0.00186721 |
| Partner B Class 2 Skills | 0.00182561 | 0.00242293 | 0.00190308 |
| Partner C Class 3 | 0.00192134 | 0.00236901 | 0.00190956 |
Table 1. These experiments compare different pretraining datasets, collected together with multiple data foundry partners, split across different classifications (i.e. modes) of data collection. Class 1 involves data on specific tasks, Class 3 involves do-anything type data, and Class 2 is everything in between. Different partners also have different operations, and we can use these experiments to evaluate between partners to iterate and provide feedback on what data to collect, how to do it, and which methods improve models the most.
More on these learnings in future posts.
Citation
Please cite this work as
Generalist AI Team, "GEN-0: Embodied Foundation Models That Scale with Physical Interaction", Generalist AI Blog, Nov 2025.
Or use the BibTeX citation:
@article{generalist2025gen0,
author = {Generalist AI Team},
title = {GEN-0: Embodied Foundation Models That Scale with Physical Interaction},
journal = {Generalist AI Blog},
year = {2025},
note = {https://generalistai.com/blog/nov-04-2025-GEN-0},
}
author = {Generalist AI Team},
title = {GEN-0: Embodied Foundation Models That Scale with Physical Interaction},
journal = {Generalist AI Blog},
year = {2025},
note = {https://generalistai.com/blog/nov-04-2025-GEN-0},
}